Cannabis has always been interesting to me. Whether it be used recreationally or medically; I believe that the product itself has many benefits.

What I'm Trying to Achieve
There is an obscene amount of strains out there and each one has different desired effects on people.
So what I wanted to do was create an application that returns the top 5 strains that best fits the user’s inputs. The best part about this is that you can configure how many predictions you want. Meaning it can recommend any amount of strains best suited for you based on how many different strains you want. As I was the machine learning engineer for this project, it was my responsibility to train a model that is usable for the Web team to utilize.
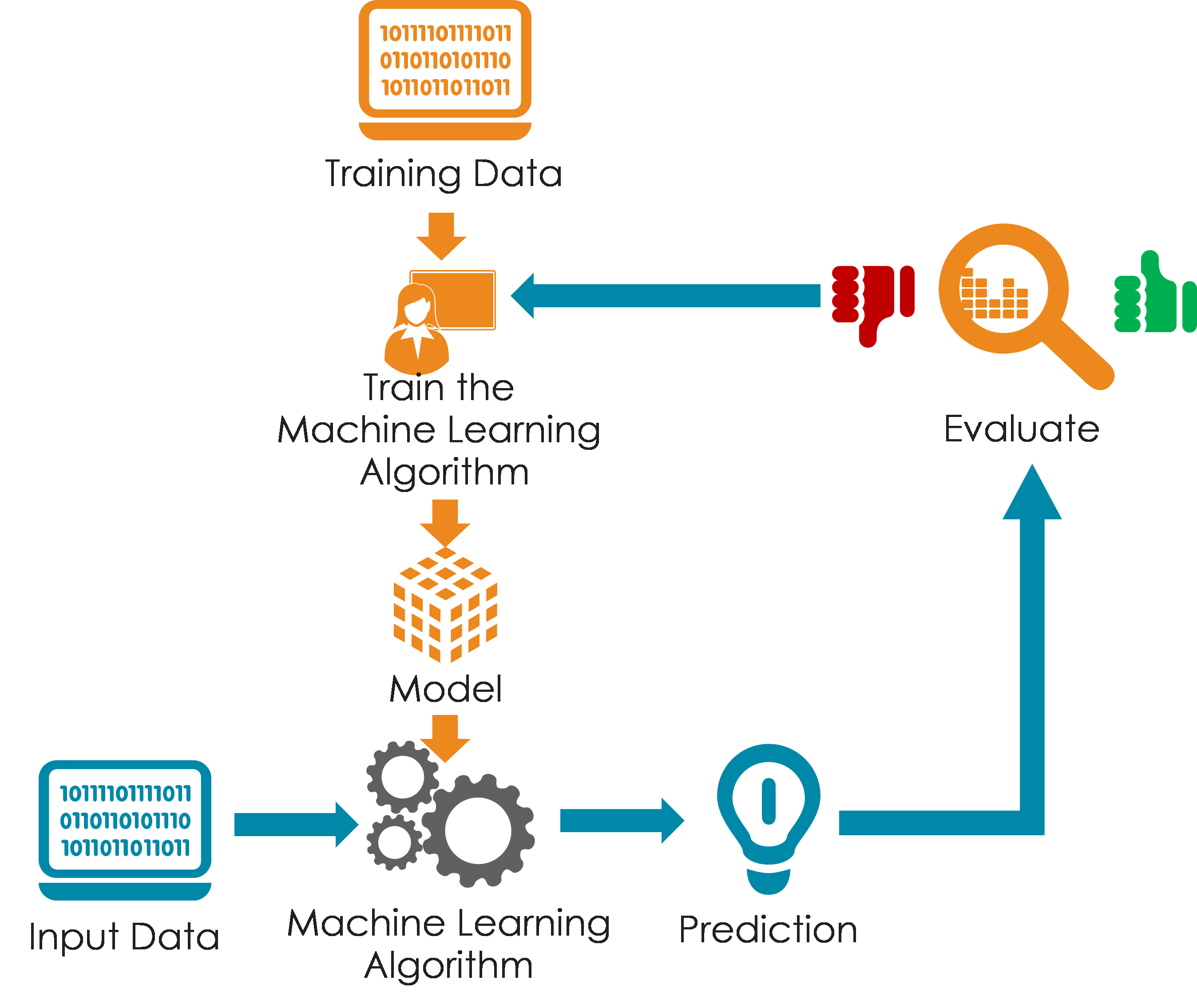
Process
I had to merge 2 different datasets to get both the strain names and their descriptions. Aftewards I had to tokenize the string from the all_text column in the dataset and apply NLP to it which I then put into a ‘lemmas’ column. I then had to vectorize the lemmas column so that our model is trained to recognize certain weights associated with certain words. After I vectorized my lemmas columns, all that was left was fitting that into my Nearest Neighbors model.

Challenges
A challenge that I had intially was finding datasets that I was able to use for this project. Although there is a lot of data out there in regards to cannabis. It was difficult to procure a dataset that not only has a substantial amount of strains, but also a description associated with each strain to apply NLP to. Another challenge I encountered was finding out what exactly should I keep from the original dataset. Every feature in a dataset contains valuable information unless its a duplicate. I had to put myself in the users shoes here and decide what I would want to know alongside a recommended strain’s name. I also had trouble pickling and using my model. To ensure that our app is up and running by the deadline; I decided for us to go a live training route for our model.

Final Result
Our application works great; it is able to return the appropriate strains based on the user’s inputs. The only issue would be the amount of time it would take to generate each list of recommendations. The time isn’t absurdly long; we are talking maybe 2-3 seconds per generated list. However, having 2-3 seconds spent everytime you want to run the app is something that is not ideal. I hope to resolve this sometime in the near future.
